-
COVID-19 ( 2 - 데이터 크롤링 )데이터 분석/코로나19 2021. 2. 6. 11:18
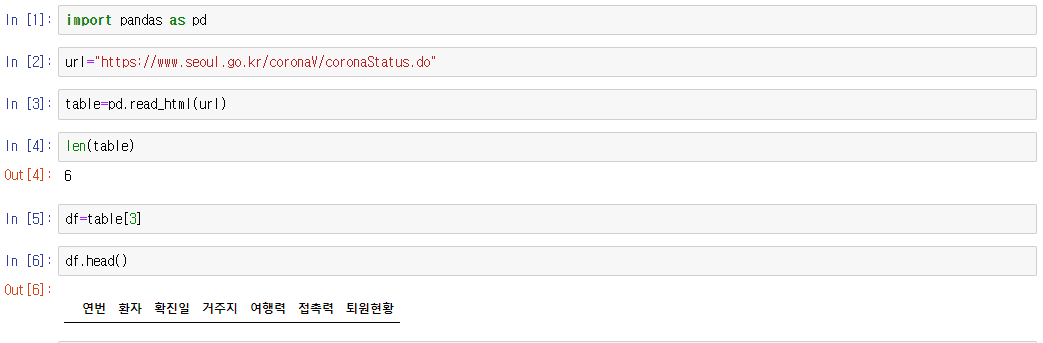
서울시에서 발생하는 코로나 데이터를 얻기 위해서 우선 서울시 코로나 확진자 현황 홈페이지에 접속을 하였다. (https://www.seoul.go.kr/coronaV/coronaStatus.do). 홈페이지에 들어가면 '서울 확진자 현황'이라는 테이블 형태의 표를 확인이 가능하다.

우선 해당 홈페이지의 URL을 그대로 가져와 jupyter notebook에서 분석을 시작해보겠다.
=> 서울시 코로나 현황 URL을 가져온 결과 컬럼명만 나오고 데이터가 나오지 않았음을 알 수 있다. 3차 대유행이 일어나기 전인 6월에 해당 URL을 가져왔을 당시에는 데이터가 이상없이 나왔지만 현재는 그렇지 않다. 1명의 확진자가 자기가 걸렸는지도 모른체 수십, 수백 명의 접촉자를 만들고 그로인해 환자가 기하급수적으로 증가함에 따라 데이터의 저장형식을 바꾼 것같은 생각이 들었다. 그래서 개발자 모드( F12 )에 진입해 해당 위치에 URL주소를 가져와야 했다.

-> 해당 URL을 임포트 했던 requests를 통해 가져왔고 'Response [200]'이라는 메시지가 출력되므로써 데이터를 이상없이 가져왔다는 것을 확인할 수 있었다.

-> 데이터에는 확진자의 정보가 있었으며 records_total이 10000개인 이유는 확진자가 너무 많다보니 서울시 홈페이지에서 10000명까지의 정보와 그 이후 발생한 환자들의 정보를 구분을 해놨기때문에 우선 첫 발생부터 10000번째까지 확진자 정보를 가져왔다.

-> 앞서 봤던 data_json의 'data' 정보를 데이터프레임 형식으로 변환하였고 100개의 확진자 정보( 데이터프레임은 인덱스가 0번부터 시작하기 때문에 0~99번까지의 정보가 들어가 있다. ) 와 알 수 없는 컬럼명이 나타난 것을 확인할 수 있으며, 컬럼명은 추후에 변환할 예정이다.
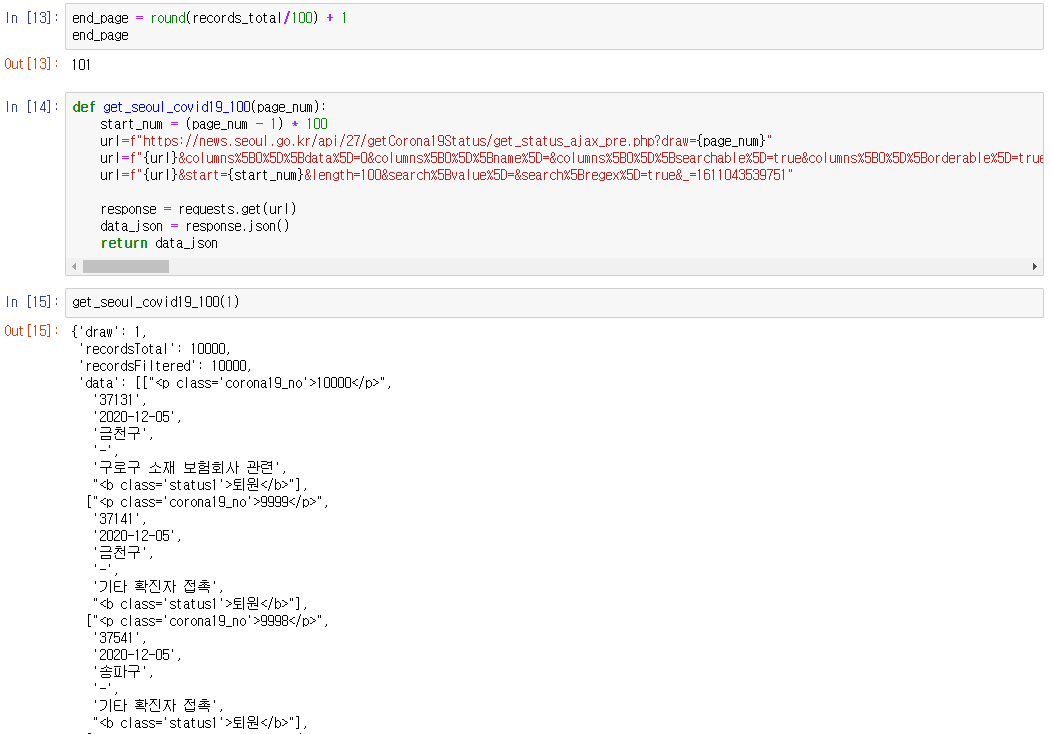
-> end_page를 정해주고 각각에 페이지에 들어갈 100개의 데이터를 가져오는 함수 'def get_seoul_covid19_100( )'를 만들고 인자로 page_num을 넣어주었다.

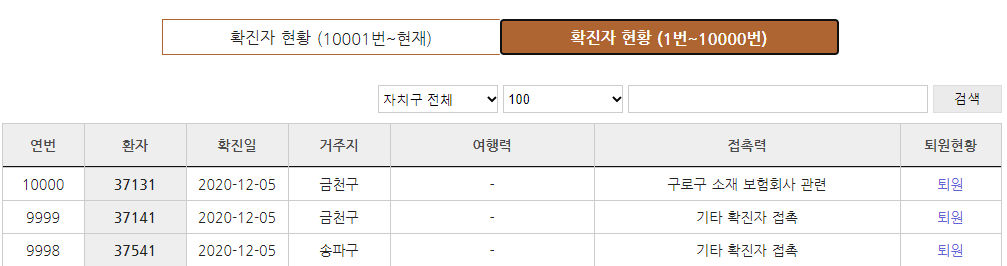
-> 함수에 인자로 첫 번째 페이지의 정보를 인자로 넣어주었고, 함수가 올바르게 작동하는지 확인하기 위해 서울시 코로나 현황 홈페이지에 들어가 확인해본 결과 환자번호 '37131', '37141', '37541'에 대한 정보가 똑같이 출력되었음을 알 수 있다. 하지만 'def get_seoul_covid19_100( )'는 한페이지에 있는 100개의 정보만 가져오는 함수다. 우리에게는 10000개의 정보가 필요하기 때문에 모든 데이터를 가져오는 함수가 필요하다.
( 이렇게 분석을 하면서 가장 느낀 부분은 다음으로 내가 무엇을 해야하는지에 대한 생각들이 존재 해야한다. 가설을 검증하기 위해선 데이터도 중요하지만 검증을 위해서 내가 데이터를 어떻게 만지려고 하는지 머릿속에 존재해야 분석이 가능하다.)
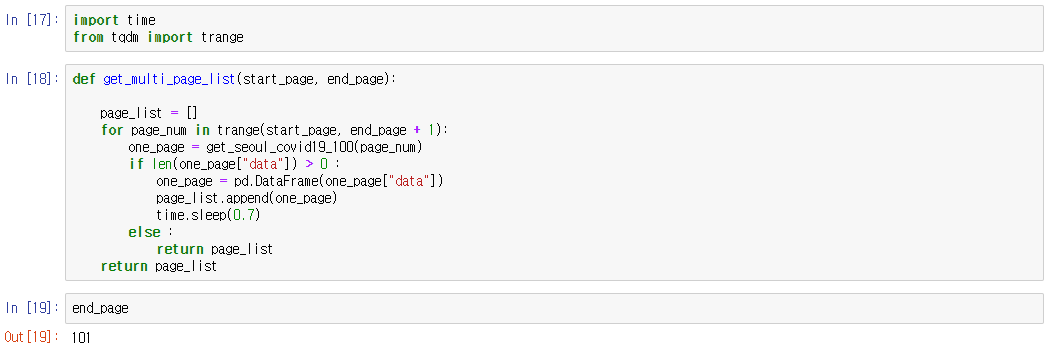
-> 새로 추가한 import time과 from tqdm import trange은 시간이 많이 소요되는 코드가 있을 때 얼마만큼 진행되는지에 대한 작업진행률을 표시해준다.
-> 함수 'def get_multi_page_list( )'의 인자로 start_page, end_page를 넣어줘서 전체 페이지를 읽어오도록 하였다. for문 시작 전에 page_list를 만들어주고 초기화 시켜줘야한다. for문에서는 처음으로 100개의 정보를 가져오는 one_page를 만들고 one_page에 있는 data 값( 위에 확인해보면 'data': [["<p class='corona19_no'>10000</p>"가 있다. )이 0보다 클 때 100개의 정보가 각각의 페이지에 쌓여가는 형태로 진행된다. )
-> 진행작업률과 작업을 완료하는데 걸린 시간을 나타내주며, 해당 코드는 첫 번째 페이지만 나타내는 코드이다.
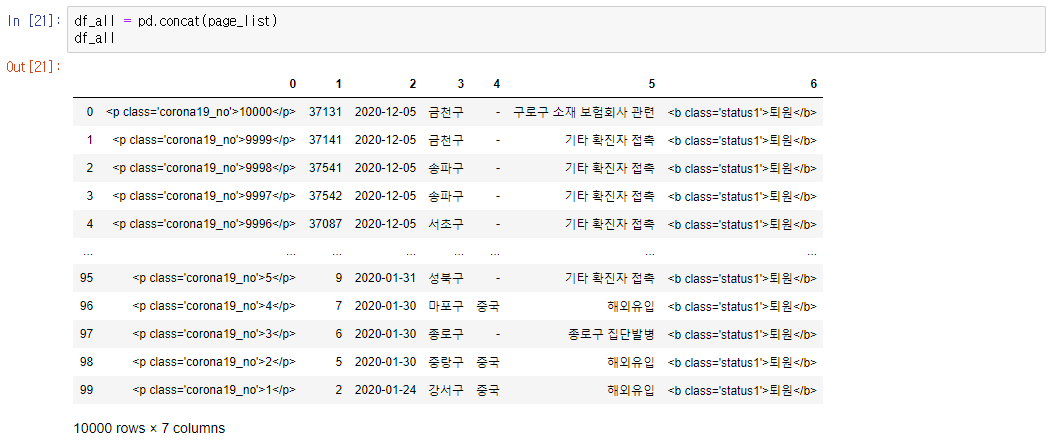
-> 판다스의 concat( )를 이용하여 page_list에 있는 페이지들을 모두 하나로 합쳐주었고 서울에서 처음 확진자가 발생한 20년 1월 24일부터의 정보가 df_all에 담겨져있는 것을 확인 할 수 있다.

-> 맨 처음 df 컬럼을 가져와 df_all의 컬럼명으로 바꿔줌으로써 1~10000번째 확진자 정보를 서울시 코로나 홈페이지와 똑같이 구현하였다. 지금까지의 과정과 똑같은 방식으로 데이터를 읽어와 10000~1월 31일까지의 확진자 정보를 가져올 수 있다.

-> 1~10000번 확진자 정보와 10000번 이후부터 1월31일까지의 확진자 정보는각각 df_all, df_all_2에 들어가 있는 것을 확인할 수 있다.

-> 이전과 똑같이 판다스의 concat( )을 사용해서 하나로 합쳤으며, head( )와 tail( )로 최근 정보와 마지막 정보를 확인함으로써 1번째 확진자 정보에서부터 1월31일 기준 확진자의 정보까지 모두 가져왔음을 알 수 있다.
'데이터 분석 > 코로나19' 카테고리의 다른 글
COVID-19 ( 7 - 분석 및 검증) (0) 2021.02.11 COVID-19 ( 5 - 분석 및 검증) (0) 2021.02.08 COVID-19 ( 4 - 데이터 전처리 ) (0) 2021.02.06 COVID-19 ( 3 - 데이터 전처리 ) (0) 2021.02.06 COVID-19 (1) (0) 2021.02.05