-
분류 - 6Python Machine Learning/분류 2020. 8. 12. 17:58
이번에는 XGBoost와 LightGBM을 활용해 캐글의 산탄데르 고객 만족 데이터 세트에 대한 고객 만족 여부를 예측해보겠습니다. 클래스 레이블 명은 TARGET이며, 이 값이 1이면 불만을 가진 고객, 0이면 만족한 고객으로 모델의 성능 평가는 ROC-AUC로 평가하겠습니다.
산탄데르 고객 만족 예측 예제
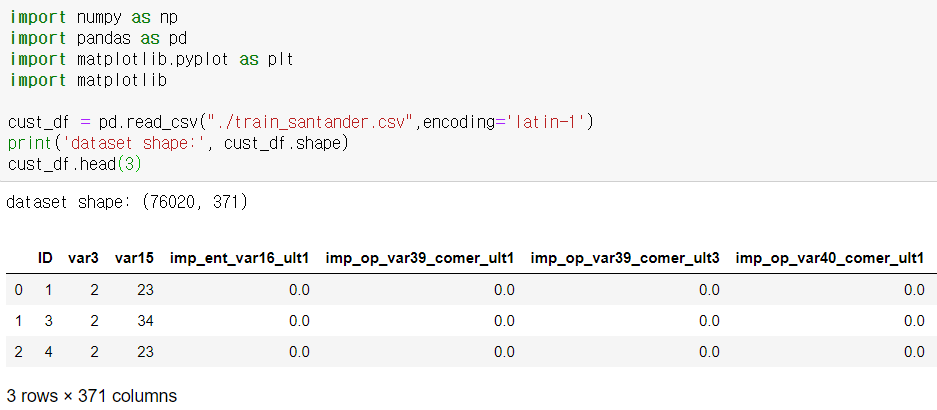
학습 데이터를 데이터프레임으로 로딩-> 76020의 데이터와 371개의 피처 
피처의 타입과 null값 확인 
레이블인 target 속성의 값의 분포 확인 
각 피처의 분포도 확인 -> var3 칼럼의 min 값이 -99999이며 이 것은 NaN이나 특정 예외 값을 -99999로 변환했을 것. 
var3에는 -99999값이 116개가 있음 
-99999는 편차가 심해 값이 가장 많은 2로 변환하고 ID피처는 단순 식별자이기 때문에 드롭 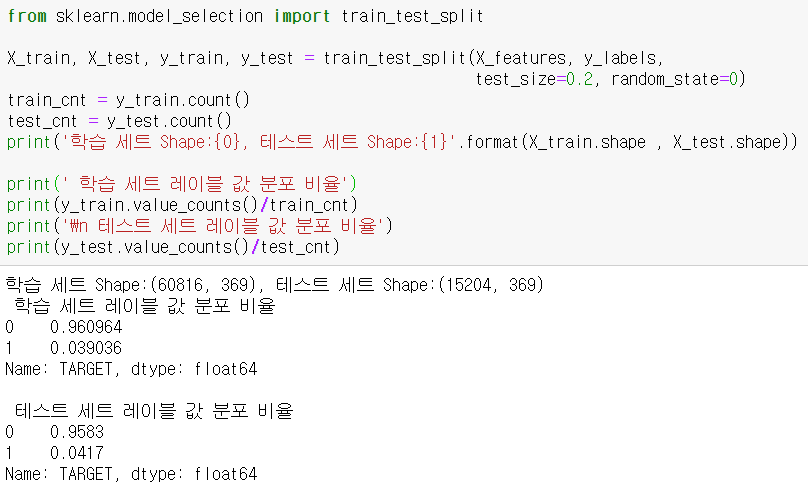
학습과 성능 평가를 위해서 원본 데이터 세트에서 학습 데이터 세트와 테스트 데이터 세트를 분리 ->원본 데이터와 유사하게 학습과 테스트 데이터 세트 모두 TARGET의 값의 분포가 전체 데이터의 4%정도의 불만족 값으로 만들어짐. XGBoost 모델 학습

성능 평가 지표 auc, 조기 중단 파라미터 100으로 설정하고 학습 
테스트 데이터 세트로 예측 시 ROC AUC는 약 0.8419 XGBoost의 하이퍼 파라미터 튜닝

n_estimator를 100으로 줄이고, 조기 중단을 30으로 줄여서 테스트 
하이퍼 파라미터를 튜닝한 후 ROC AUC 수치가 약간 개선되었음 
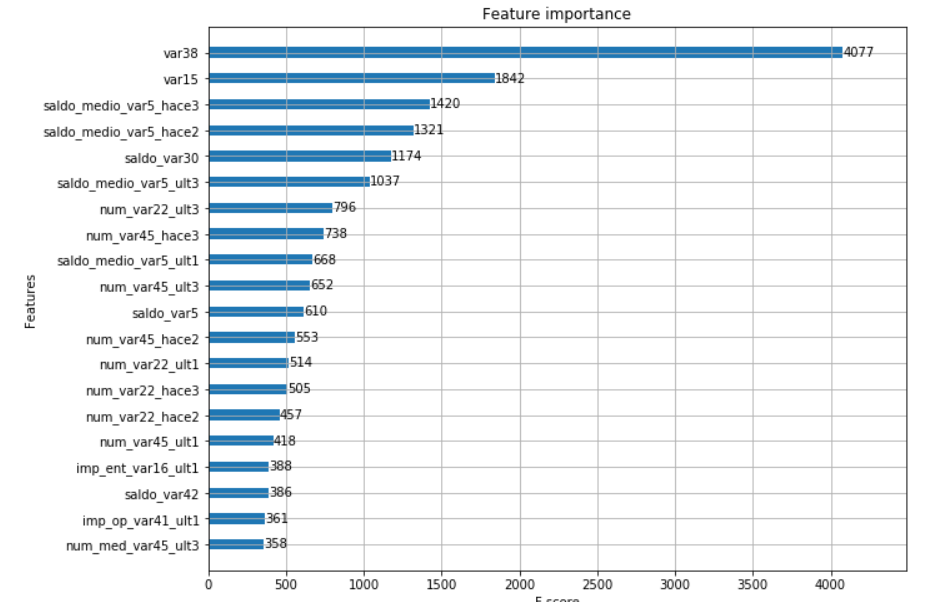
피처 중요도 시각화 LightGBM 모델 학습


LightGBM 하이퍼 파라미터 튜닝


하이퍼 파라미터를 튜닝한 후 ROC AUC 수치가 약간 개선되었음