-
사이킷런 ( Scikit-learn ) - 6Python Machine Learning/Scikit-learn 2020. 7. 22. 18:17
데이터 전처리란?
- ML 알고리즘은 데이터에 기반하고 있는데 어떤 데이터를 입력으로 가지느냐에 따라 결과도 크게 달라집니다. ( Garbage-In -> Garbage-Out ) 그렇기 때문에 데이터 전처리는 ML알고리즘만큼 중요합니다.
- 데이터 전처리의 기본 사항으로는 다음과 같습니다.
- 사이킷런의 ML알고리즘은 문자열 값을 입력 값으로 허용하지 않기때문에 모든 문자열 값은 인코딩돼서 숫자형으로 변환해야 합니다.
- 문자열 피처는 텍스트형 피처를 의미하며 텍스트형 피처는 피처 벡터화등의 기법으로 벡터화하거나 불필요한 피처판단되면 삭제하는게 좋습니다.
- 결손값, 즉 NaN, Null값이 허용되지 않으며 이러한 Null값은 고정된 다른 값으로 변환해야 합니다.
- 데이터 전처리가 하는 역할은 다음과 같습니다.
- 데이터 클린징
- 결손값 처리 ( Null/NaN 처리 )
- 데이터 인코딩( 레이블, 원-핫 인코딩 )
- 데이터 스케일링
- 이상치 제거
- Feature 선택, 추출 및 가공
데이터 인코딩
- ML알고리즘은 숫자형값만 받아들이기때문에 숫자형으로 변환해줘야 하는데 변환을 가능하도록 해주는 유형으로는 데이터 인코딩이라하며 데이터 인코딩에는 레이블 인코딩과 원-핫 인코딩이 있습니다.
레이블 인코딩(Label encoding)
- 카테고리 피처를 코드형 숫자 값으로 변환하는 것입니다.

labelEncoder를 객체로 생성 후 fit ( ) 과 transform( ) 으로 label 인코딩 수행. --> 'TV', '냉장고' 가 숫자형 0, 1로 바뀐 것을 알 수 있습니다.

--> 문자열이 어떤 숫자 값으로 인코딩됐는지 확인하기 위해서는 객체의 classes_ 속성값으로 확인하면 됩니다.

--> inverse_transform( )을 통해 인코딩된 값을 디코딩할 수 있습니다.
레이블 인코딩의 단점
- 일괄적인 숫자 값으로 변환이 되면서 숫자에는 값의 크고 작음에 대한 특성이 작용하기 때문에 몇몇 ML 알고리즘에서 예측 성능이 떨어지는 경우가 발생할 수 있습니다.
ex) A : 1, B : 2로 변환되면, 1보다 2가 더 큰 값이라 판단하여 ML알고리즘에서 가중치가 부여되거나 더 중요하게 인식할 가능성이 발생 가능.
- 이러한 문제젖ㅁ을 해결하기 위한 이코딩 방식이 원-핫( One-Hot Encoding )입니다.
원-핫 인코딩(One-Hot encoding)
- 행 형태로만 되어있는 피처의 고유 값을 열 형태로 새로운 피처를 추가해 고유 값에 해당하는 칼럼에만 1을 표시하고 나머지 칼럼에는 0을 표시하는 방식입니다.
- 사이킷런에서 One-Hot encoding 클래스로 변환하기 위해서는 모든 문자열 값이 숫자형 값으로 변환돼야 한다는 것이며, 입력 값으로 2차원 데이터가 필요하다는 점입니다.

숫자형 변환과 2차원 데이터 형태 --> 8개의 레코드와 1개의 칼럼을 가진 원본 데이터가 8개의 레코드와 6개의 칼럼을 가진 데이터로 변환되었습니다.
--> 즉 원본 데이터 ㅡ> 숫자로 인코딩( 레이블 인코딩 ) ㅡ> 원-핫 인코딩의 변환 절차를 가집니다.

원-핫 인코딩을 지원하는 API : get_dummies( ) --> get_dummoes( ) API를 이용하면 OneHotEncoder와 다르게 문자열 카테고리 값을 숫자 형으로 변환할 필요 없이 바로 변환할 수 있습니다.
피처 스케일링과 정규화
- 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업을 피처 스케일링( feature scaling )이라고 하며 대표적인
방법으로는 표준화( standardization )와 정규화( Normalization )가 있습니다.
표준화( standardization )
- 데이터의 피처 각각이 평균이 0이고 분산이 1인 가우시안 정규 분포를 가진 값으로 변환하는 것을 의미합니다.
정규화( Normalization )
- 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 개념입니다.
사이킷런에서는 혼선을 바지하기 위해 표준화와 정규화를 피처 스케일링으로 통칭하고 선형대수 개념의 정규화를 벡터 정규화로 지칭하며, 사이킷런에서 제공하는 대표적인 피처 스케일링 클래스에는 standardScaler와 MinMaxScaler가 있습니다.
standardScaler
- 표준화를 지원하기 위한 클래스로 개별 피처를 평균이 0이고, 분산이 1인 값으로 변환해줍니다. 사이킷런에서 구현한 서포트 벡터 머신( SVM ), 선형 회귀, 로지스틱 회귀는 데이터가 가우시안 분포를 가지고 있다고 가정하고 구현됐기 때문에 가우시안 정규 분포를 가질 수 있도록 데이터를 변환하는 것은 매우 중요합니다.

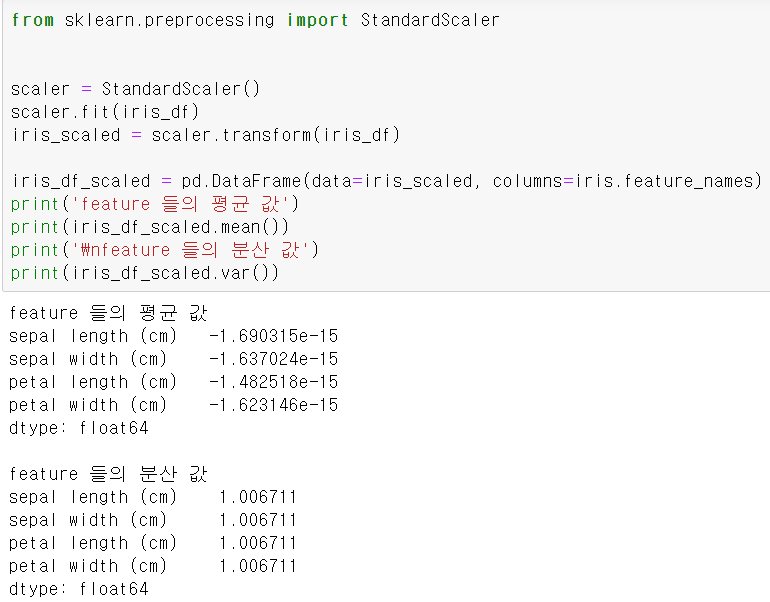
standardScaler 적용 --> standardScaler 객체를 생선한 후에 fit( ), transform( ) 메서드에 변환 대상 피처 데이터 세트를 입력하고 호출하면 간단하게 변환됩니다. ( transform( )을 호출할 때 스케일 변환된 데이터 세트가 넘파이의 ndarray이므로 이를 DataFrame으로 변환해 평균값과 분산 값을 확인해야함. )
--> 모든 칼럼 값의 평균과 분산이 각각 0과 1에 가까운 값으로 변환됐음을 알 수 있습니다.
MinMaxScaler
- 데이터값을 0과 1사이의 범위 값으로 변환합니다 ( 음수값이 존재하면 -1~1값으로 변환 )
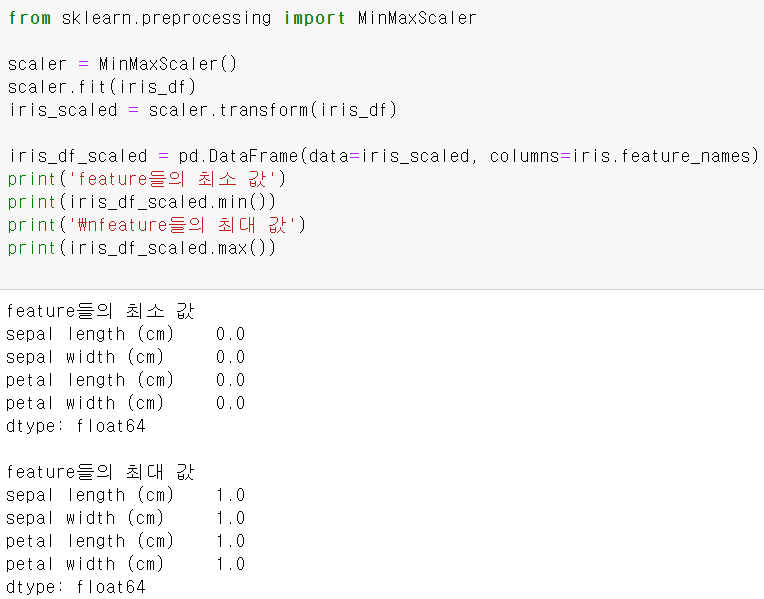
MinMaxScaler 적용 'Python Machine Learning > Scikit-learn' 카테고리의 다른 글
사이킷런 ( Scikit-learn ) - 7 (0) 2020.07.22 사이킷런 ( Scikit-learn ) - 5 (0) 2020.07.22 사이킷런 ( Scikit-learn ) - 4 (0) 2020.07.21 사이킷런 ( Scikit-learn ) - 3 (0) 2020.07.21 사이킷런 ( Scikit-learn ) - 2 (0) 2020.07.21