데이터 분석/뉴욕시 택시 수요 예측
베이스라인 모델 구축
Data Analytics
2021. 5. 10. 19:22
- 성능 비교를 위한 베이스라인 모델을 구축하는 것이 목표입니다.
- 베이스라인은 비교 대상이 될 모델이기 때문에 성능이 낮다고 잘못된 것이 아닙니다.
- 단순 회귀법을 사용하여 모델을 확인해보겠습니다.
1) 라이브러리 선언
2) bigquery에서 sql 이용하여 데이터 전처리

3) train / test 데이터 세트 분리

- 여기까지 과정은 이전 게시물과 같아서 설명을 생략했습니다.
4) 베이스라인 모델
- Linear Regerssion 사용

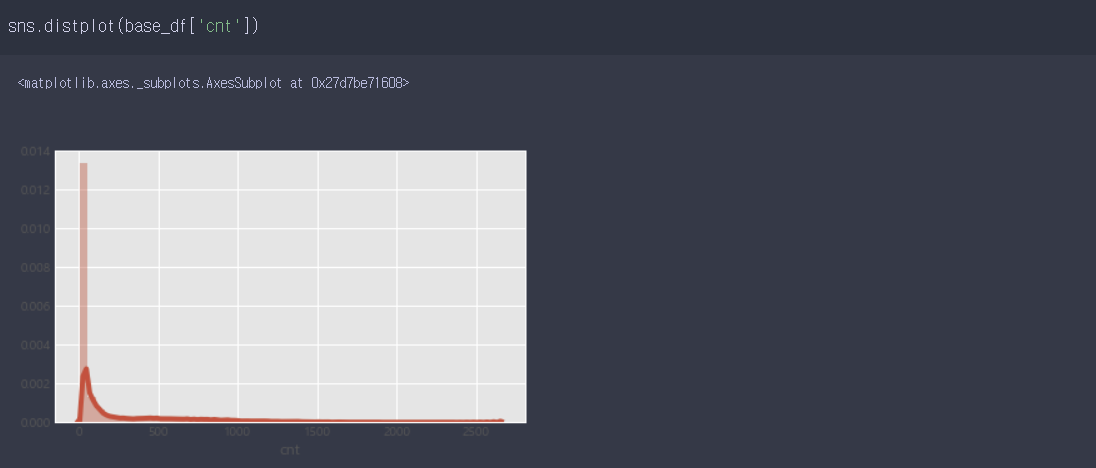
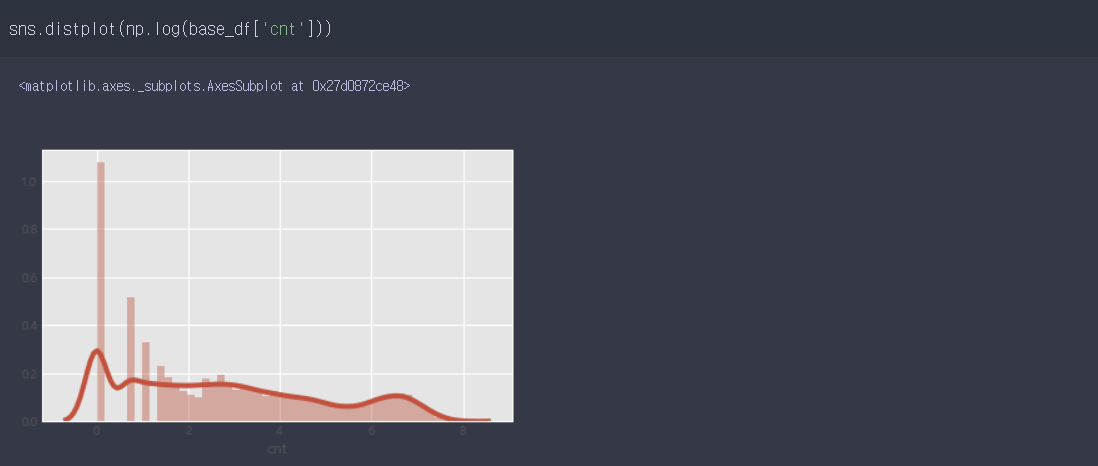
- 원본 데이터 세트에서 target 값의 분포를 확인해본 결과 target 값의 분포가 몰려있다는 것을 알 수 있습니다.
- 그래서 로그를 취해줬으며 그래프와 같이 값이 분포되었음을 확인할 수 있습니다.
5) widget 활용

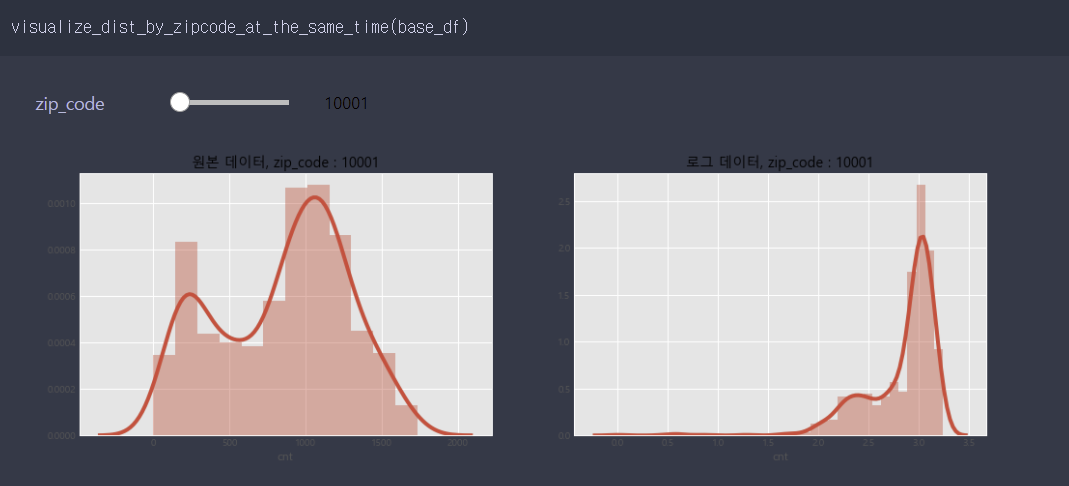
- zip_code별 log를 취하지 않았을 때와 취했을 때 target값의 분포를 widget를 활용하여 한번에 시각화 해보았습니다.
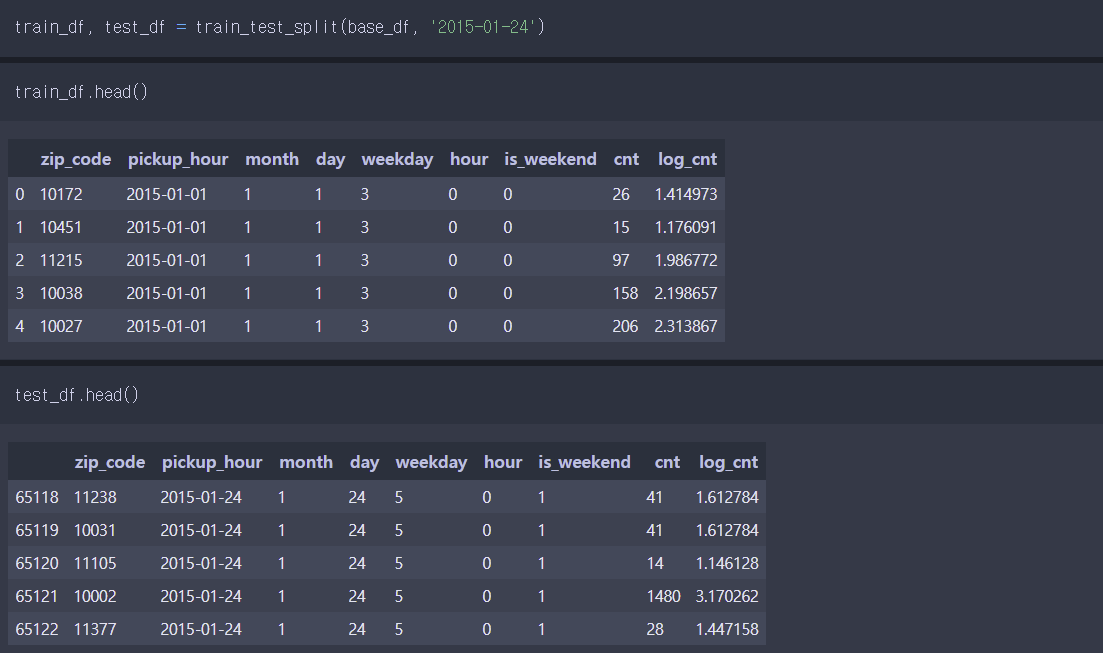
6) train / test 데이터 세트 분리

7) simple regression
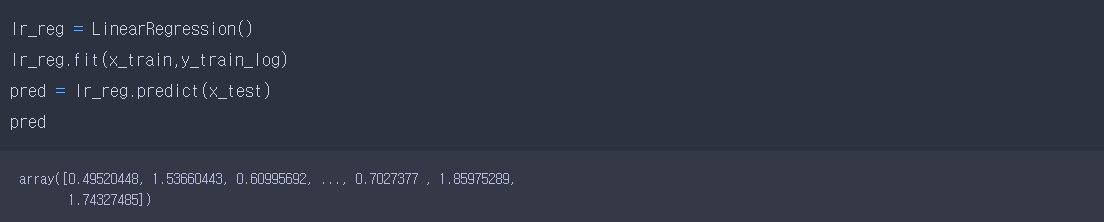
- regression을 위해 사용할 LinearRegression 객체를 생성 후 fit, predict 해준 값을 pred에 저장시켰습니다.


8) one hot encoding 후 regression



- OneHotEncoding을 하기 전과 하고난 뒤 값들을 비교해보았을 때 하고난 뒤 성능이 더 좋아진 것을 알 수 있다.