GMM( gaussian mixture model )
[ 개요 ]
- 군집화를 적용하고자 하는 데이터가 여러 개의 가우시안 분포를 모델을 섞어서 생성된 모델로 가정해 수행하는 방식
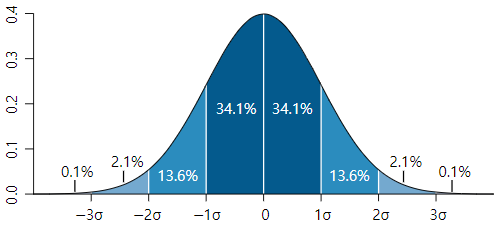
- 정규분포로도 알려진 가우시안 분포는 좌우 대칭형의 종 형태를 가진 연속 확률 함수
[ 장점, 단점 ]
장점
유연하고 다양한 데이터 세트에 적용 가능
단점
군집화를 위한 수행 시간이 오래 걸림
[ GMM 군집화 ]
GMM 군집화 방식은 서로 다른 정규 분포에 기반해 군집화를 수행하는 것으로 여러 데이터 세트가 있다면 이를
구성하는 여러 개의 정규 분포 곡선을 추출하고, 개별 데이터가 이 중 어떤 정규 분포에 속하는지 결정하는 방식.
이러한 방식을 GMM에서는 모수 추정이라 하며, 모수 추정은 대표적으로 2가지를 추정하는 것
- 개별 정규 분포의 평균과 분산
- 각 데이터가 어떤 정규 분포에 해당되는지의 확률
모수 추정을 위해 GMM은 EM( Expectation and Maximization ) 방법을 적용하며 사이킷런은 GMM의 EM 방식을 통한
모수 추정 군집화를 지원하기 위해 GaussianMixture 클래스를 지원
[ 예제 ]
붓꽃 데이터 세트를 이용해 거리 기반 군집화인 K평균과 확률 기반 군집화인 GMM을 각각 구해 비교해보는 예제

-> GaussianMixture 객체의 fit( 피처 데이터 세트 )와 predict( 피처 데이터 세트 )를 수행해 군집을 결정
-> 클러스터링 결과를 irisDF 의 'gmm_cluster' 컬럼명으로 저장
-> target 값에 따라서 gmm_cluster 값이 어떻게 매핑되었는지 확인.
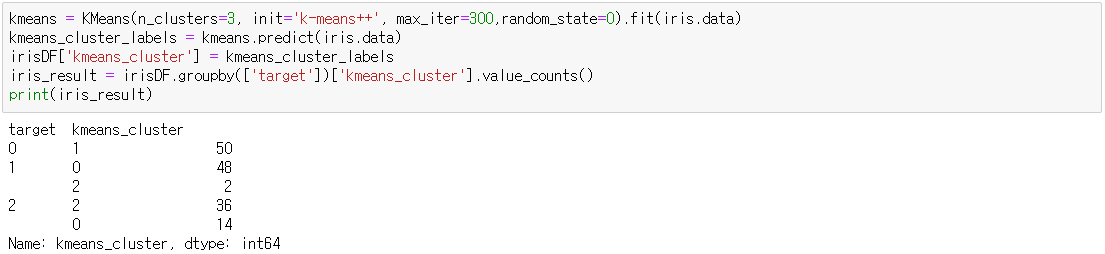
-> GMM의 군집화 결과가 더 효과적인 분류 결과 도출
=> 어느 알고리즘이 뛰어나다는 의미가 아니라 붓꽃 데이터 세트가 GMM 군집화에 더 효과적이라는 의미