-
문서 군집화Python Machine Learning/텍스트 분석 2021. 1. 16. 20:21
0. Opinion Review 데이터 세트를 이용한 문서 군집화
- Opinion Review 데이터 세트는 51개의 텍스트 파일로 구성돼 있으며, 파일은 호텔, 자동차, 전자제품 사이트에서 가져온 리뷰 문서.
1. 데이터 로딩

1) 개별 파일의 파일명은 filename_list로, 개별 파일의 파일 내용은 dataframe 로딩 후 다시 string으로 변환해 opinion_text list로 취합.
2) 개별 파일을 읽어 dataframe으로 생성하고 절대 경로로 주어진 파일명을 가공.
3) 파일명 list와 파일 내용 list에 파일명과 파일 내용을 추가.
4) 파일명 list와 파일 내용 list 객체를 dataframe으로 생성.
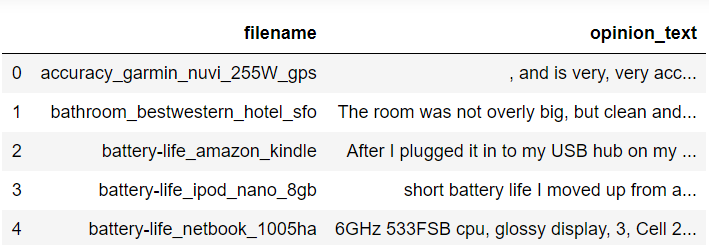
=> 파일 이름만으로 어떤 제품/서비스에 대한 리뷰인지 파악 가능.
2. Lemmatization을 위한 함수 생성

3. TF-IDF 피처 벡터화, TfidfVectorizer에서 피처 벡터화 수행 시 Lemmatization을 적용하여 토큰화

-> TfidfVectorizer의 fit_transform( )의 인자로 document_df DataFrame의 opinion_text 칼럼을 입력하면 개별 문서 텍스트에 대해 TF-IDF 변환된 피처 벡터화된 행렬을 구할 수 있음.
4. 3개의 군집으로 K-Means군집화 후 군집화된 그룹별로 데이터 확인

[ Cluster #0 ]

=> 전자기기에 대한 리뷰로 군집화
[ Cluster #1 ]

=> 호텔에 대한 리뷰로 군집화
[ Cluster #2 ]
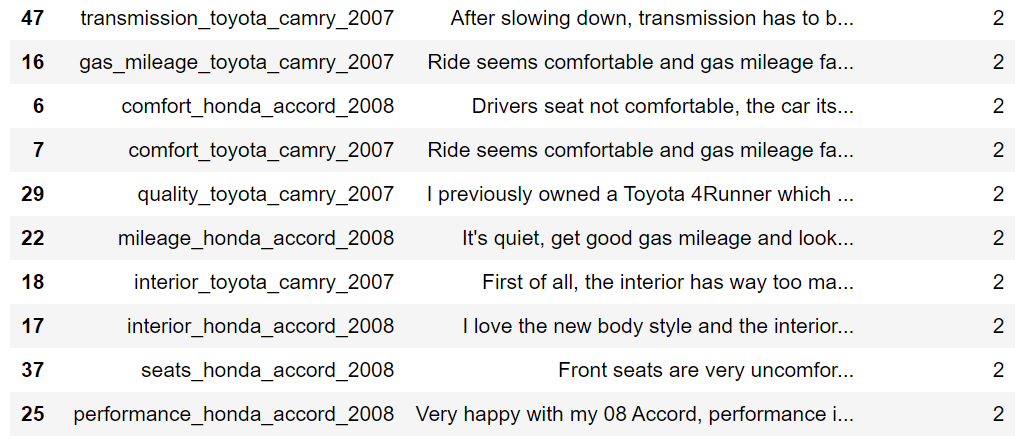
=> 자동차에 관한 리뷰로 군집화
5. 군집(Cluster)별 핵심 단어 추출하기

-> KMeans객체의 cluster_centers_ 속성은 개별 피처들의 클러스터 중심과의 상대 위치를 정규화된 숫자값으로 표시
0~1까지의 값으로 표현되며 1에 가까울 수록 중심에 더 가깝다는 의미

-> argsort( )[ :,::-1]를 이용하면 cluster_centers 배열 내 값이 큰 순으로 정렬된 위치 인덱스 값 반환되며 군집 중심점(centroid)별 할당된 word 피처들의 거리값이 큰 순으로 값을 구할 수 있음.
-> 개별 군집별 정보를 담을 데이터 초기화.
-> cluster_centers_.argsort()[:,::-1] 로 구한 index 를 이용하여 top n 피처 단어를 구함.
-> top_feature_indexes를 이용해 해당 피처 단어의 중심 위치 상댓값 구함 .
-> cluster_details 딕셔너리 객체에 개별 군집별 핵심 단어와 중심위치 상대값, 그리고 해당 파일명 입력.
=> get_cluster_details( ) 를 호출하면 cluster_details를 반환( 개별 군집번호, 핵심 단어, 핵심단어 중심 위치 상댓값, 파일명 속성 값 정보가 포함)
6. 클러스터별 top feature들의 단어와 파일명 출력

=> get_cluster_details( )와 보기 좋게 표현을 위해 만든 print_cluster_details( )함수를 호출.
호출 시 인자는 KMeans 군집화 객체, 파일명 추출을 위한 document_df dataframe, 핵심 단어 추출을 위한 피처명 리스트, 전체 군집 개수, 핵심 단어 추출 개수.
피처명 리스트는 get_feature_names( )로 추출

=> Cluster #0에서는 'screen', 'battery','lift' 과 같은 화면과 배터리 수명 등이 핵심 단어로 군집화
Cluster #1에서는 'room' ,'hotel','service','location' 과 같은 방과 서비스등이 핵심 단어로 군집화
Cluster #2에서는 'interior' ,'seat' ,'mileage' ,'comfortable' 과 같은 실내 인테리어, 좌석, 연료 효율등이 핵심 단어로 군집화
'Python Machine Learning > 텍스트 분석' 카테고리의 다른 글
감성분석 - IMDB 영화평( 비지도 학습기반 분석 ) (0) 2021.01.16 감성 분석 - IMDB 영화평 (0) 2020.12.24 텍스트 분류 실습 - 뉴스그룹 분류(2) (0) 2020.12.23 텍스트 분류 실습 - 뉴스그룹 분류 (0) 2020.11.27 Bag of Words - BOW (0) 2020.11.14